一文理解 Stable Diffusion 的生成图片原理
Stable Diffusion 是一种人工智能图像生成模型,它可以根据你输入的文字描述(Prompt)生成对应的图片。比如你输入“一只猫在草地上”,它就能生成一张猫在草地上的图片。
它的核心原理是 扩散模型(Diffusion Model),这是一种通过“加噪声”和“去噪声”来生成图像的技术。
Stable Diffusion 的工作原理
Stable Diffusion 的工作原理可以分为两个主要阶段:
加噪声:把一张清晰的图片变成一团随机的噪声。
去噪声:把一团随机的噪声变成一张清晰的图片。
下面我们详细讲讲这两个阶段。
阶段一:加噪声(扩散过程)
通俗理解: 想象你有一张清晰的画,然后你不断地往画上撒墨水,直到画完全被墨水覆盖,变成一团乱七八糟的东西。这个过程就是“加噪声”。
技术细节: * 从一张清晰的图片开始。
逐步向图片添加随机噪声(可以理解为一堆随机的像素点)。
经过很多步之后,图片就变成了一团完全随机的噪声。
阶段二:去噪声(逆扩散过程)
通俗理解:
现在你有一团被墨水覆盖的画,但你记得画原本的样子。于是你一点点地把墨水擦掉,最终恢复了原来的画。这个过程就是“去噪声”。
技术细节: * 从一团随机的噪声开始。
通过一个神经网络(通常是 U-Net),逐步预测并去除噪声。
每一步都让图片变得更清晰,最终生成一张符合你描述的图片。
文字提示(Prompt)的作用
在去噪声的过程中,Stable Diffusion 会根据你输入的文字提示(Prompt)来调整生成图片的内容。比如你输入“一只猫在草地上”,模型就会在去噪声的过程中,让图片逐渐变成“猫在草地上”的样子。
通俗理解: 文字提示就像是你给画家的指令。你告诉画家“画一只猫在草地上”,画家就会根据你的指令一点点地把墨水擦掉,最终画出一只猫在草地上的画。
模型的核心组件
Stable Diffusion 的核心组件包括:
- U-Net:
一个神经网络,负责预测并去除噪声。
它通过多次迭代,逐步把噪声从图片中去除。
- CLIP:
一个文本-图像匹配模型,负责理解文字提示(Prompt)。
它帮助模型在去噪声的过程中,让生成的图片符合文字描述。
- VAE(变分自编码器):
负责把图片压缩成低维表示(Latent Space),然后再解压缩回图片。
这样可以大大减少计算量,提高生成速度。
Stable Diffusion 的工作流程
输入文字提示:比如“一只猫在草地上”。
生成随机噪声:从一团随机的噪声开始。
去噪声:
使用 U-Net 逐步去除噪声。
同时根据 CLIP 的指导,调整图片内容,使其符合文字提示。
- 输出图片:生成一张清晰的“猫在草地上”的图片。
举个栗子
假设你想生成一张“一只猫在草地上”的图片:
输入提示:"a cat on the grass"
生成随机噪声:Stable Diffusion 从一团随机的噪声开始。
去噪声:
模型通过 U-Net 逐步去除噪声。
同时根据 CLIP 的指导,让图片逐渐变成“猫在草地上”的样子。
- 输出图片:生成一张清晰的“猫在草地上”的图片。
总结
Stable Diffusion 是一种通过“加噪声”和“去噪声”生成图片的 AI 模型。
它根据你输入的文字提示(Prompt),逐步把一团随机的噪声变成一张清晰的图片。
核心组件包括 U-Net、CLIP 和 VAE,它们分别负责去噪声、理解文字提示和压缩/解压缩图片。
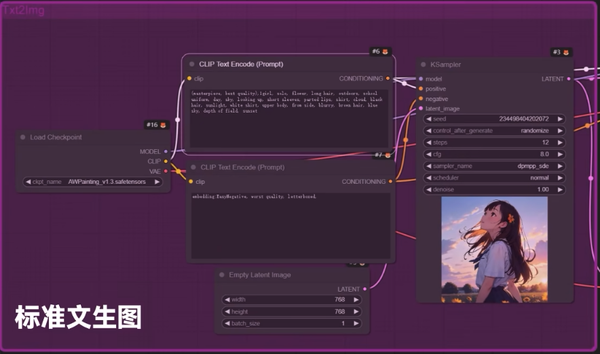
KSampler
KSampler 是什么?
KSampler 是 ComfyUI 中的一个重要组件,它的作用是控制生成图像的过程。你可以把它想象成一个“魔法搅拌机”,它负责将一些随机的“噪声”慢慢搅拌成一张完整的图片。
输入:KSampler 接收一些初始的随机噪声(可以理解为一团模糊的、乱七八糟的东西)。
输出:经过 KSampler 的处理,最终生成一张清晰的、符合你要求的图片。
KSampler 的工作原理
KSampler 的核心是 扩散模型(Diffusion Model) 的采样过程。简单来说,扩散模型是通过以下步骤生成图片的:
加噪声:从一张清晰的图片开始,逐步添加噪声,直到图片变成一团完全随机的噪声。
去噪声:从一团随机的噪声开始,逐步去除噪声,最终恢复成一张清晰的图片。
KSampler 就是负责“去噪声”这一步的。它通过多次迭代,一点点地把噪声去掉,最终生成一张清晰的图片。
KSampler 的关键参数

KSampler 有几个重要的参数,你可以通过调整这些参数来控制生成图片的效果:
Steps(步数)
作用:控制去噪声的步骤数量
通俗理解:就像画画时,你画得越细致,画的次数越多,最终的效果就越好。步数越多,生成的图片质量通常越高,但计算时间也会更长。
建议值:一般设置在 20-50 之间。
CFG Scale(分类器自由引导尺度)
作用:控制生成图片与输入提示(Prompt)的匹配程度。
通俗理解:就像你告诉画家“画一只猫”,CFG Scale 越高,画家就越严格地按照你的要求画;CFG Scale 越低,画家就越自由发挥。
建议值:一般设置在 7-12 之间。
Sampler(采样器)
作用:选择去噪声的算法。
通俗理解:就像选择不同的“搅拌方式”,有的方式快但粗糙,有的方式慢但精细。
常见选项:
Euler:速度快,适合大多数情况。
DDIM:适合需要精细控制的场景。
DPM++:质量高,但速度较慢。
Seed(种子)
作用:控制随机噪声的初始状态。
通俗理解:就像种菜的种子,不同的种子会长出不同的菜。同样的种子会生成同样的图片。
建议值:如果你想生成相同的图片,就固定 Seed;如果想生成不同的图片,就随机设置 Seed。
Denoise(去噪强度)
作用:控制去噪声的程度。
通俗理解:就像调节“清晰度”,值越高,图片越清晰;值越低,图片越模糊。
建议值:一般设置在 0.7-1.0 之间。
KSampler 的使用场景
KSampler 通常用于以下场景:
生成图片:根据文字提示(Prompt)生成图片。
图片修复:对模糊或损坏的图片进行修复。
风格迁移:将一张图片转换成另一种风格。
VAE
VAE(Variational Autoencoder,变分自编码器)是一种神经网络模型,它的作用是把高维数据(比如图片)压缩成一个低维的表示(Latent Space),然后再从这个低维表示中恢复出原始数据。
编码器(Encoder):把图片压缩成低维表示。
解码器(Decoder):把低维表示恢复成图片。
为什么要压缩成低维表示?
图片通常是非常高维的数据。比如一张 512x512 的彩色图片,它的维度是 512x512x3(3 表示 RGB 三个通道),总共需要处理 786,432 个像素点!直接处理这么高维的数据会非常耗费计算资源。
通过 VAE 把图片压缩成低维表示,可以大大减少计算量,同时保留图片的关键信息。以下是具体原因:
好处一:减少计算量
通俗理解: 想象你要处理一本厚厚的书,但你没有时间读完每一页。于是你找到书的“摘要”,只读摘要就能了解书的主要内容。VAE 的作用就是生成这个“摘要”。
技术细节: * 图片的高维数据(像素点)被压缩成一个低维向量(比如 64x64x4,总共 16,384 个值)。
- 这样,Stable Diffusion 只需要处理低维数据,而不是原始的百万级像素点,计算量大大减少。
好处二:提高生成速度
通俗理解: 如果你要画一幅画,直接在 A4 纸上画会比在墙上画快得多。VAE 就是把“墙上的画”缩小成“A4 纸上的画”,让你能更快地完成。
技术细节: * 在低维空间中进行去噪声和生成操作,速度会快很多。
- 生成完成后,再通过解码器把低维表示恢复成高维图片。
好处三:保留关键信息
通俗理解: 虽然低维表示是压缩后的数据,但它保留了图片的关键信息,就像“摘要”保留了书的核心内容。
技术细节: * VAE 在压缩过程中会学习图片的“潜在特征”,比如形状、颜色、纹理等。
- 这些特征足以让模型在低维空间中完成去噪声和生成操作。
好处四:降低模型复杂度
通俗理解: 如果你要解决一个复杂的问题,先把问题简化会更容易。VAE 就是把高维的图片生成问题简化成低维的生成问题。
技术细节: * 在低维空间中,模型的训练和推理会更稳定。
- 低维表示还能减少过拟合的风险,让模型更容易泛化到新的数据。
Stable Diffusion 中的 VAE
在 Stable Diffusion 中,VAE 的作用如下:
- 编码阶段:
把原始图片压缩成低维表示(Latent Space)。
这个低维表示会被输入到扩散模型中进行去噪声操作。
- 解码阶段:
*把去噪声后的低维表示恢复成高维图片。
- 最终生成一张清晰的图片。
举个栗子
假设你想生成一张“一只猫在草地上”的图片:
输入图片:一张 512x512 的图片(高维数据)。
编码:VAE 把图片压缩成 64x64x4 的低维表示。
去噪声:Stable Diffusion 在低维空间中进行去噪声操作。
解码:VAE 把去噪声后的低维表示恢复成 512x512 的图片。
输出:生成一张清晰的“猫在草地上”的图片。
总结VAE 是 Stable Diffusion 能够高效生成高质量图片的关键技术之一! 使用 VAE 把图片压缩成低维表示的好处包括:
减少计算量:处理低维数据比高维数据更高效。
提高生成速度:在低维空间中操作更快。
保留关键信息:低维表示足以描述图片的核心特征。
降低模型复杂度:简化问题,让模型更容易训练和推理。
文档信息
版权声明:可自由转载(请注明转载出处)-非商用-非衍生
发表时间:2025年1月10日 11:39